Can computers predict the future? We desperately want them to, if you count the sheer tonnage of science-fiction tales we’ve consumed over the decades featuring all-knowing techno-oracles using their massive calculating power to work out every detail in the same way IBM’s Deep Blue games out a chess match. The magnificent Minds modeling the behavior of entire civilizations while calculating hyperspace jumps in Iain M. Banks’ Culture novels. C-3PO rattling off the odds of survival to Han Solo in Star Wars.
For now, however, silicon seers aren’t prophesizing the distant future like A.I. gods. Instead, they’re creeping into the near future, gradually extending the reach of what computer engineers variously call foresight, anticipation, and prediction. Autonomous cars slam on the brakes seconds before an accident occurs. Stock-trading algorithms foresee market fluctuations crucial milliseconds in advance. Proprietary tools predict the next hit pop songs and Hollywood movies. The ways in which computation is sidling up to the future reminds me of the old William S. Burroughs line: “When you cut into the present, the future leaks out.”
Better near-future predictions are beginning to appear in all sorts of consumer products, too. We used to laugh at wacky Amazon recommendations and Microsoft’s infamous Clippy popping up to ineffectually “help” you write a letter in Word, but the predictions we see these days more often feel eerily accurate.
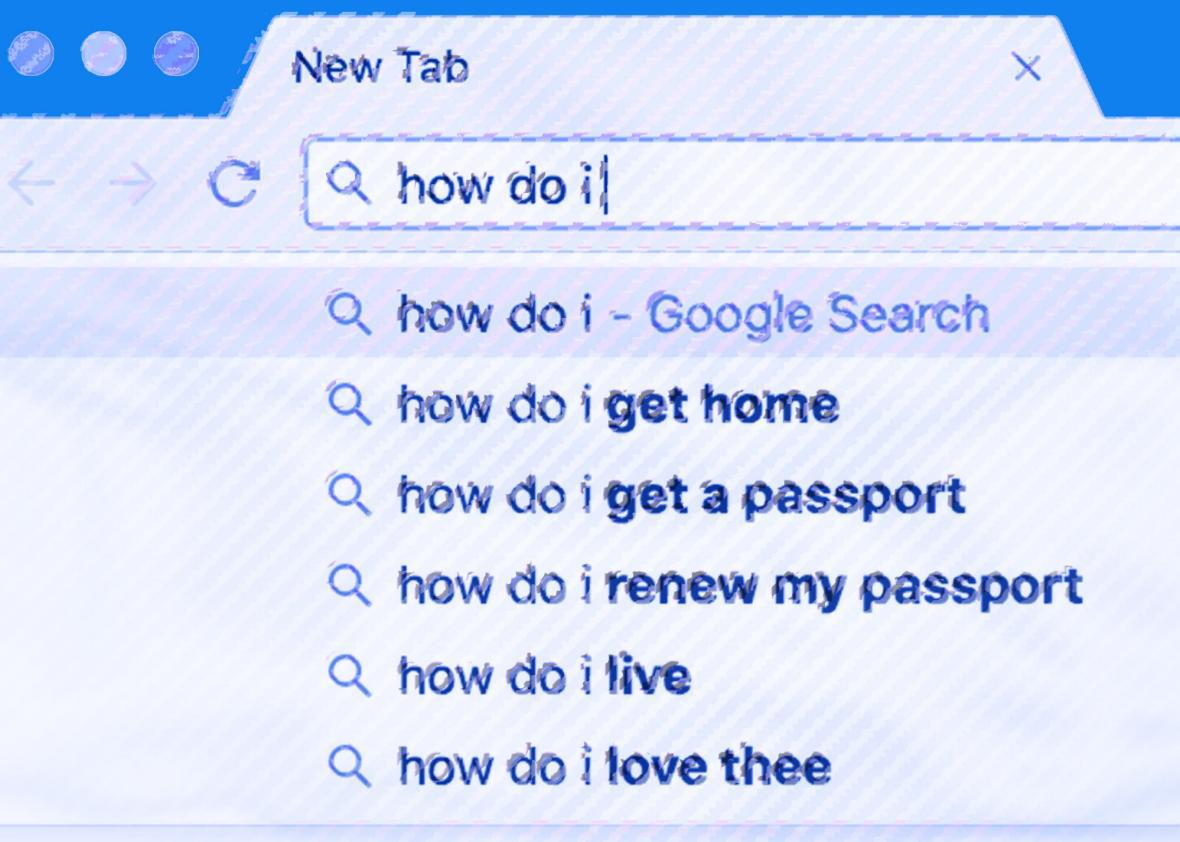
Consider Google autocomplete, those helpful little strings of suggested text that pop up as you start typing in a search query. As a genre of prophecy, this might seem pretty lame. But consider how often the typical internet user relies on those little pop-ups every day, using them not just to save typing a few more letters but as a kind of microquery in its own right: a rapid spell-check, fact check, and zeitgeist check all rolled into one. Does the name you’re searching for pop up with “girlfriend” or “married” appear after it? What does Google suggest after you type in “how do i”? (Google’s suggestions for me are “get home; renew a passport; get a passport; love thee.” Thanks, Google.) These predictions are based on the words thousands of other people typed into their search bars, but they are also customized for you based on your own browsing history, location, and whatever else Google might care to reference in its extensive file on you.
This may seem like an unremarkable convenience, but it is also a way to reinvent the relationship we all have with “now” and “soon.” Years ago, Google realized that people get annoyed by delays in response time—even if it’s less than a second. In fact, humans can be bothered by any lags that are perceptibly longer than the speed at which our own nervous system can respond to stimuli (about 250 milliseconds). So if Google wants to get you something now, it strives to do it in about the time it takes for your foot to report that you have stubbed your toe just now. In doing so, it pushes the envelope of instant gratification by attempting to guess what you want before you even articulate it. Autocomplete leaps ahead of now to offer you the near future on a silver platter.
The predictive quality of the algorithm gets more interesting when you pick an autocomplete suggestion that wasn’t quite what you were searching for but was close enough that you went along with it because you are a lazy mammal. For in this matter of your query about cats or clown anxieties, Google has not just predicted the future but changed it. Now multiply that possibility by the 3.5 billion or more search queries the company processes each day.
Autocomplete provides just one small example of the many ways algorithms’ predictions shape the future. Think about your relationship with Facebook: the primary source of news for many people. The social network has deployed extensive predictive resources to figure out populate your feed with content and connections that will keep you coming back to the site. Are you liberal or conservative? Rich or poor? What’s your ethnicity, your geographical location, your favorite brand of clothing? Advertisers also want to know—and have been flocking to Facebook’s increasingly formidable abilities to hone in on your demographics, influences, and preferences. As the ads become better targeted, they’re more likely to influence the products you purchase, gifts you get, trips you take, neighborhood you move to, or when you make major decisions such as changing jobs or getting married. And the algorithms’ decisions about who to share your next big life event with continue the feedback loop for others. That data may also be used to discriminate against you. It may have already done so, as it did with an old Facebook advertising system that allowed clients to exclude particular “ethnic affinities” from seeing housing, credit, and employment ads. (The company now claims it’s enacting policies to prevent this kind of deliberate bias.)
Even if there’s no large manila folder in Palo Alto labeled “black people on Facebook,” the algorithms are written to differentiate perceived demographics in an instrumental way. The program will populate your feed with posts and ads it thinks you—or rather, its sometime uncanny but ultimately imprecise understanding of you—will enjoy, each with the potential to become a self-fulfilling prophecy of what you will like. The feed look similar for those it thinks are similar to you but very different for someone it associates with other demographic and social categories. This is yet another kind of future-shaping: It manipulates the information we’re aware of—not just the things we concentrate on, but the things on the horizon we are vaguely aware of. But those things on the margins often come back and become the future. Since we have only so much capacity to think about the decisions that aren’t in the immediate now, catching a glimpse of something out of the corner of the eye—say a promo for a sneaker company your friends on Facebook like—can influence you later because the ad puts those kicks onto the fairly short list of things you might think about wanting later. It also makes the decision to buy sneakers from that company easier for you (a fact advertisers know full well). Our algorithms snuggle right in there between our complacency and our anxiety to fill the empty places. That ad for a realtor or an engagement ring might be close enough to the thing we thought we wanted that it’s easier just to click on it. But by doing so, we become the flattened versions of ourselves that the algorithm predicted, and along the way, limit the possibilities of our experience. Lazy mammals.
This kind of prediction will only become more prevalent, and more seductive in its convenience, as algorithms improve and we feed them more data with our queries, our smart home devices, our social media updates, and our expanding archives of photos and videos. Facebook, for one, is beavering away at literally reading your mind. At its annual developer conference, it unveiled a new technology that can transcribe text directly from thought. It made for a very cool demo, but it also opened up a host of questions. What if, like autocomplete, the text is almost what you thought? What if your brain, an incredibly adaptable tool, reshapes its thinking to better suit the algorithm, and you find yourself thinking in Facebook, like you dreamed in French for a few weeks before the big Advanced Placement exam? Now the futures you can think about are shaped by somebody else’s code.
This is an extreme version of how computers might predict the future, at least in its particulars. But in its generalities, it’s happening all the time. We slice and dice the present in millions of different models, and making all sorts of assumptions about what we can and can’t predict. The more we depend on computers to handle the near-future for us (where do I turn? what should I read? who should I meet?), the more limited our map of the present and potential future becomes. We’re reversing William S. Burroughs: cutting up the future and turning it into discrete pieces of the present that have been denatured of ambition, of mystery, of doubt, and of deeper human purpose. We may get an answer to our question, but we don’t know what it means.
For most of us, most of the time it’s not the long-term, hazy-outline future that matters. It’s the next five minutes, the next day, the next line of conversation. These are the predictions that algorithms want to make for us because they shape the real decisions that move our lives forward. But the future isn’t just about the coming decisions in our field of view. It’s the blank space on the map, the zone of possibility and hope. On good days, it’s the telescope through which we see our best selves finally coming into being. But these algorithms can be so compelling in the ways that end up mapping out our near future that they obscure the slow, dramatic changes that might take decades to pull off. Algorithms are so effective at filling every available moment of free time with pings and updates that they foreclose vital opportunities for daydreams and self-reflection: the times when you suddenly realize you have to quit your job or write a book or change who you are. We’ve all had that experience of discovering a whole new version of ourselves totally unpredicted by any model. Those futures are not something we should give up to an algorithm.
This article is part of Future Tense, a collaboration among Arizona State University, New America, and Slate. Future Tense explores the ways emerging technologies affect society, policy, and culture. To read more, follow us on Twitter and sign up for our weekly newsletter.